A closer look Karpathy's microgpt
Andrej Karpathy recently released a beautiful piece of code: a complete GPT implementation in ~200 lines of pure Python with zero dependencies. I took some time to look at the evolution of this code through its revision history, and found some surprisingly cool tips about deep learning, software engineering, and the art of simplifying things to their core essence.
A few weeks ago, Andrej Karpathy released microgpt.py—a single-file GPT implementation that trains and generates text using nothing but Python’s standard library. No PyTorch, no NumPy, no dependencies at all. The code is beautiful in its minimalism, but what I find even more fascinating is its revision history. Watching Karpathy iterate on this code reveals lessons that go far beyond the code itself.
As he puts it in the opening docstring:
“The most atomic way to train and run inference for a GPT in pure, dependency-free Python. This file is the complete algorithm. Everything else is just efficiency.”
That last line is profound. Let’s dig into what we can learn from this code and its evolution.
Simplicity is the Ultimate Sophistication
“Simplicity is the ultimate sophistication.” — Leonardo da Vinci
It is mind-boggling that the core tech behind the AI revolution can fit in a 200-line Python script. Okay, this may be an oversimplification, but you get the idea.
Looking at the revision history, you can see Karpathy actively removing complexity with each revision.
The Autograd Implementation is a Masterclass in Minimalism
The Value class that implements automatic differentiation is perhaps the most instructive part of the code. Looking at the revision history, we can see a beautiful simplification.
Before (early revisions): Each operation defined its own _backward closure:
class Value:
def __init__(self, data, _children=(), _op=''):
self.data = data
self.grad = 0
self._backward = lambda: None # default: do nothing
self._prev = set(_children)
self._op = _op
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data + other.data, (self, other), '+')
def _backward():
self.grad += out.grad
other.grad += out.grad
out._backward = _backward
return out
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data * other.data, (self, other), '*')
def _backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
def backward(self):
# ... topological sort into `topo` ...
self.grad = 1
for v in reversed(topo):
v._backward() # call each node's closure
Each each operation is built with a _backward() that uses the upstream gradient to update local gradient. But notice the overhead: every operation creates a new closure that captures self, other, and out. That’s a lot of function objects.
After (final version): Store local gradients as data, not code:
class Value:
__slots__ = ('data', 'grad', '_children', '_local_grads')
def __init__(self, data, children=(), local_grads=()):
self.data = data
self.grad = 0
self._children = children
self._local_grads = local_grads # just numbers!
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data + other.data, (self, other), (1, 1))
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data * other.data, (self, other), (other.data, self.data))
def backward(self):
# ... topological sort into `topo` ...
self.grad = 1
for v in reversed(topo):
for child, local_grad in zip(v._children, v._local_grads):
child.grad += local_grad * v.grad
The trick here is to rely on the consistency of the chain rule: child.grad += local_grad * parent.grad. Or in aother words, the donwstream gradient = local grad * upstream gradient.
This refactoring:
- Eliminates all closure allocations
- Reduces memory usage (hence
__slots__) - Makes the backward pass a single, uniform loop
- Makes the code easier to understand
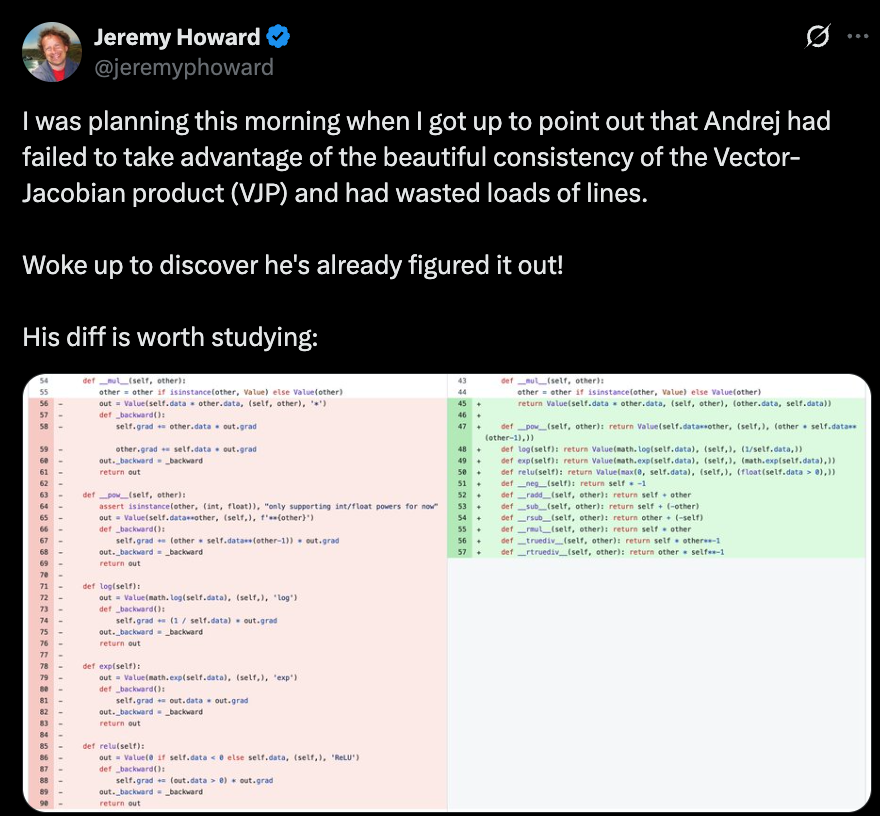
Architectural Simplifications That Don’t Hurt
The code makes several simplifications compared to GPT-2:
- RMSNorm instead of LayerNorm: Simpler (no mean subtraction, no learnable parameters)
- ReLU instead of GeLU: Much simpler to implement from scratch
- No biases: Fewer parameters, simpler code
- No weight tying: The
lm_headis separate fromwte
What’s interesting is that modern LLMs have actually adopted some of these “simplifications”—e.g., LLaMA and Mistral use RMSNorm.
Conclusion
Microgpt is more than a toy implementation—it’s a teaching tool that reveals the essence of modern language models. By studying its revision history, we see not just the final product but the process of refinement: removing unnecessary complexity, tuning hyperparameters, and finding elegant representations.
If you’re learning deep learning, I highly recommend not just reading the final code, but stepping through the revision history yourself. Each diff tells a story about what matters and what doesn’t.
As Karpathy might say: Let there be understanding.
References:
- microgpt.py - Andrej Karpathy’s original gist
- Revision history - All 13 revisions