Training LLMs to Cite their Pretraining Data
Can we train LLMs to not only answer questions, but also cite exactly where their knowledge comes from? Yes and we should train them to!
LLMs learn tons of world knowledge from pretraining, but as much of this knowledge changes, becomes obsolete, or is jus t completely wrong, an LLM user should be able to judge for themselves whether a piece of knowledge is accurate. This post is about a setup in which LLMs not only needs to answer a user prompt e.g., “who starred in Before Sunrise?”, but also provide a link to a source i.e., a citation where can this information be verified. For now, we do not need to worry about how that link looks like, what matters is that is it is unique per document.
One might ask: Can’t we already achieve this with retrieval augmented generation (RAG)? That is, retrieve relevant sources, then use the LLM to answer questions based on them, then citation is way easier since you already know the pool of documents which contain the answer. While RAG is indeed a solution to this, RAG is not neat, and adds an extra layer of complexity and overhead. Also, some works have shown that LLMs can ignore the retrieved context altogether, and just rely on memorized knowledge. More importantly, RAG can not help us attribute or support parametetric knowledge stored in the model’s weights and which not present in the retrieval corpus. Here, we are seeking a first-principles solution that can build this into the model from the ground up.
Source-Aware Training: A First Step
In our COLM ‘24 paper, Khalifa et al., 2024, we introduced the concept of intrinsic source citation.
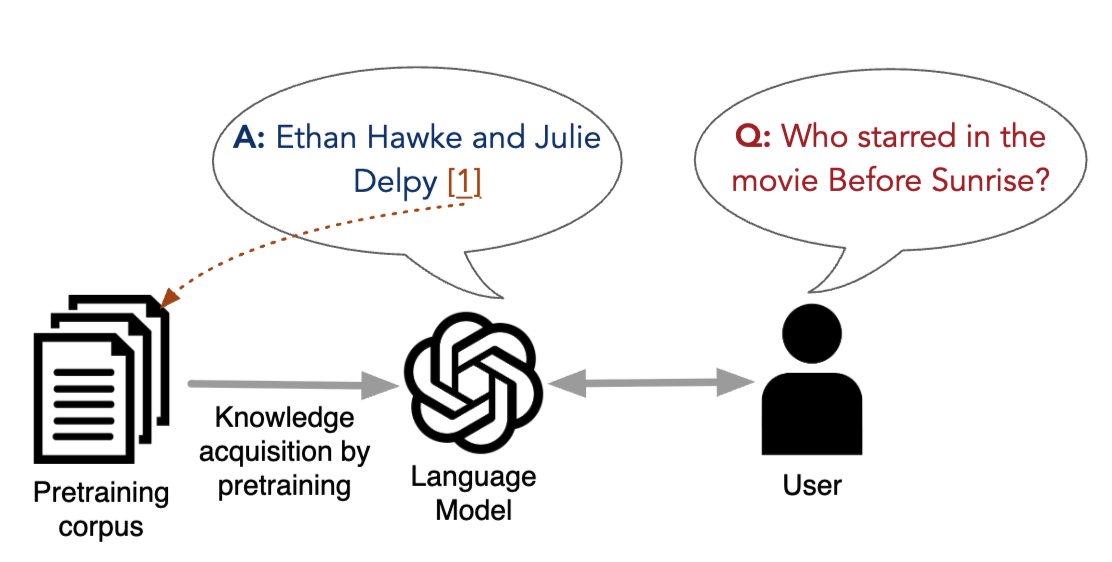
The core idea is to make LLMs aware of the source of their knowledge during pretraining, so that they can later cite the source when generating an answer. How do we do that? The simple approach we started with was to inject document identifiers during pretraining. Our approach, called source-aware training, involves two main steps:
- Document ID injection: Each document in the pretraining corpus is tagged with its unique identifier. Where we inject the identifier in the pretraining text. The goal is to teach the model to associate the knowledge i.e., facts in a document with the document ID.
- Instruction Tuning for Citation: The first step will not be sufficient to teach the model to spit the ID when needed. Here, we fine-tune the model answer questions and provide the supporting source identifier.
Our findings in this paper were mostly: We showed that it is possible to achieve that level of attribution, but with a caveat. We need data augmentation for the model to associate each individual fact with the document ID. Precisely, if we inject the ID once at the end of the document, the model simply can not associate each individual fact with the ID, it can only associate the document as a whole. In other words, it can extract individual fact and map them to the ID. We connected this to limitations of transformers identifier in Physics of LLMs 3.1. Importantly, this is achieved with minimal changes to the model architecture or training pipeline, and without a significant hit to language modeling performance.
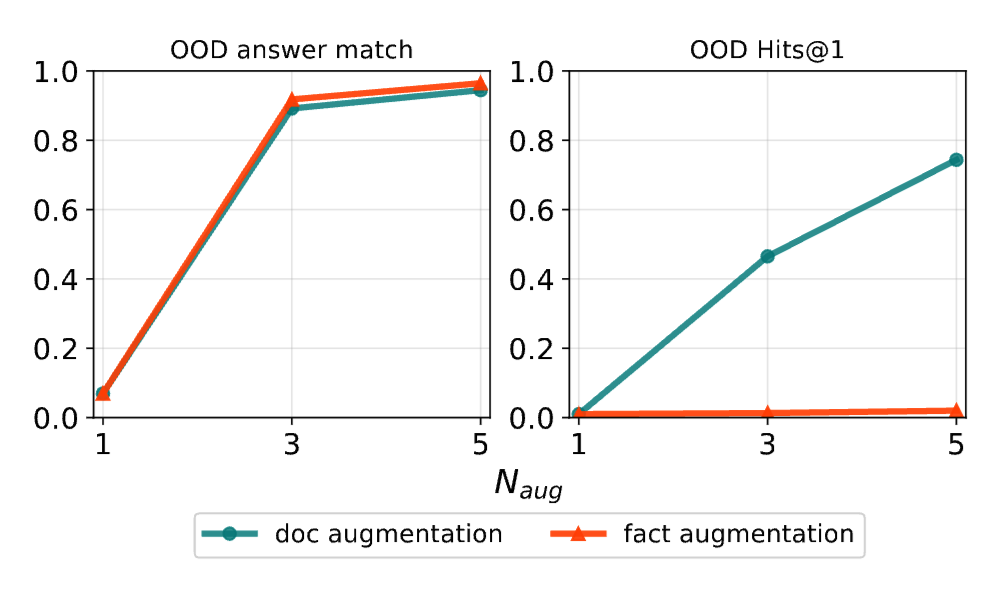
Our work was a proof of concept on synthetic data, and the next step was to scale this up to real-world knowledge. Real-world knowledge is certainly messier, and is often paraphrased or composed from multiple sources. This is where the recent work by Huang et al., 2025 makes an impressive follow-up. Their findings, which agree with ours, that step 1 of our approach (what they call “Passive Indexing”) is not enough—models struggle to attribute paraphrased or compositional facts. To address this, they propose:
- Active Indexing: During continual pretraining, the model is exposed to synthetic QA pairs that restate each fact in diverse forms and require the model to both generate content from a cited source and attribute its own answers. This is a more fancy form of the data augmentation we played with.
- Bidirectional Training: This is a clever auxiliary objective that teaches the model both to (i) answer questions given a source and to (ii) cite the source given a fact, reinforcing the fact-ID association.
Where Are We Headed?
I’m excited about a future where LLMs can not only provide answers, but cite supporting evidence of their parametric knowledge. That said, I can still see the value of RAG for working with external knowledge, and so a hybrid approach of this directions and RAG would be likely be the way to go.
**References: Khalifa et al., 2024. “Source-Aware Training Enables Knowledge Attribution in Language Models.” COLM 2024. Huang et al., 2025. “Cite Pretrain: Retrieval-Free Knowledge Attribution for Large Language Models.” arXiv:2506.17585