I'm seeking full-time research scientist roles starting early 2026. If there's a good fit, please contact me at {last_name}{first_name[0]}@umich.com.
At a very high-level, my work aims to build verifiable, reliable, and trustworthy reasoning systems. Here's a summary of my relevant work/interests:
- I am highly interested in building reliable and universal verifiers for AI reasoning. This includes process reward models for reasoning without step-level human annotations (GRACE) and proposing data-efficient generative process reward models (ThinkPRM) that can scale verifier compute by thinking longer about verification. My work also studied verification bottleneck for self-correction in reasoning.
- I am also interested in post-training techniques including aligning LLMs via energy-based models without KL pentalties, a recipe for knowedlge attribution via pretraining data citation and large-scale optimization of model merging to mitigate task tradeoffs.
- Most recently, I've focused on evaluation of AI research agents and studying issues with reward design and LLM-as-a-judge.
I am a final-year PhD candidate at the University of Michigan in Ann Arbor advised by Lu Wang and Honglak Lee. I’m currently an intern at LG AI Research working on web agents. I am interested in test-time techniques, reasoning agents, and LLM post-training. I was fortunate to work in different places with so many amazing people. In summer 2024, I was part of CodeGen team at Cohere led by Matthias Gallé where I worked on large-scale model merging. In summer 2023, I was AI2 working with Iz Beltagy and Hao Peng on training models to cite their pretraining data. In 2021, I was Amazon AWS working with Kathy Mckeown. Prior to that, I was an intern at Naver Labs Europe where I worked on Controllable Text Generation and Energy-based models with Hady Elsahar and Marc Dymetman.
Fun fact: I play the piano, write, and produce my own music.
Selected Works
(For a complete list, visit my google scholar)

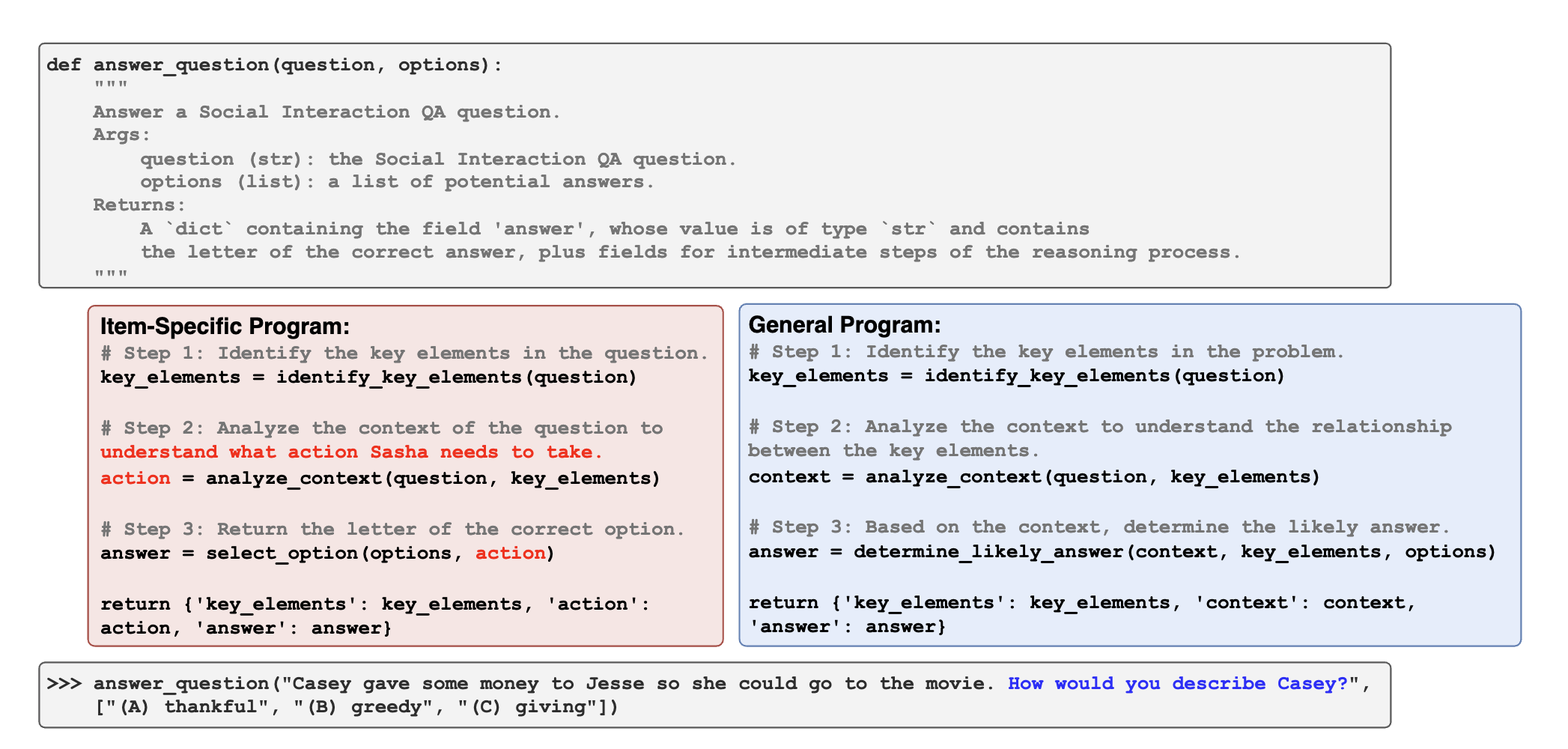
Learning to Reason via Program Generation, Emulation, and Search
Nathaniel Weir*, Muhammad Khalifa*, Linlu Qiu, Orion Weller, Peter Clark
NeurIPS 2024
Source-Aware Training Enables Knowledge Attribution in Language Models
Muhammad Khalifa, David Wadden, Emma Strubell, Honglak Lee, Lu Wang, Iz Beltagy, Hao Peng
COLM 2024
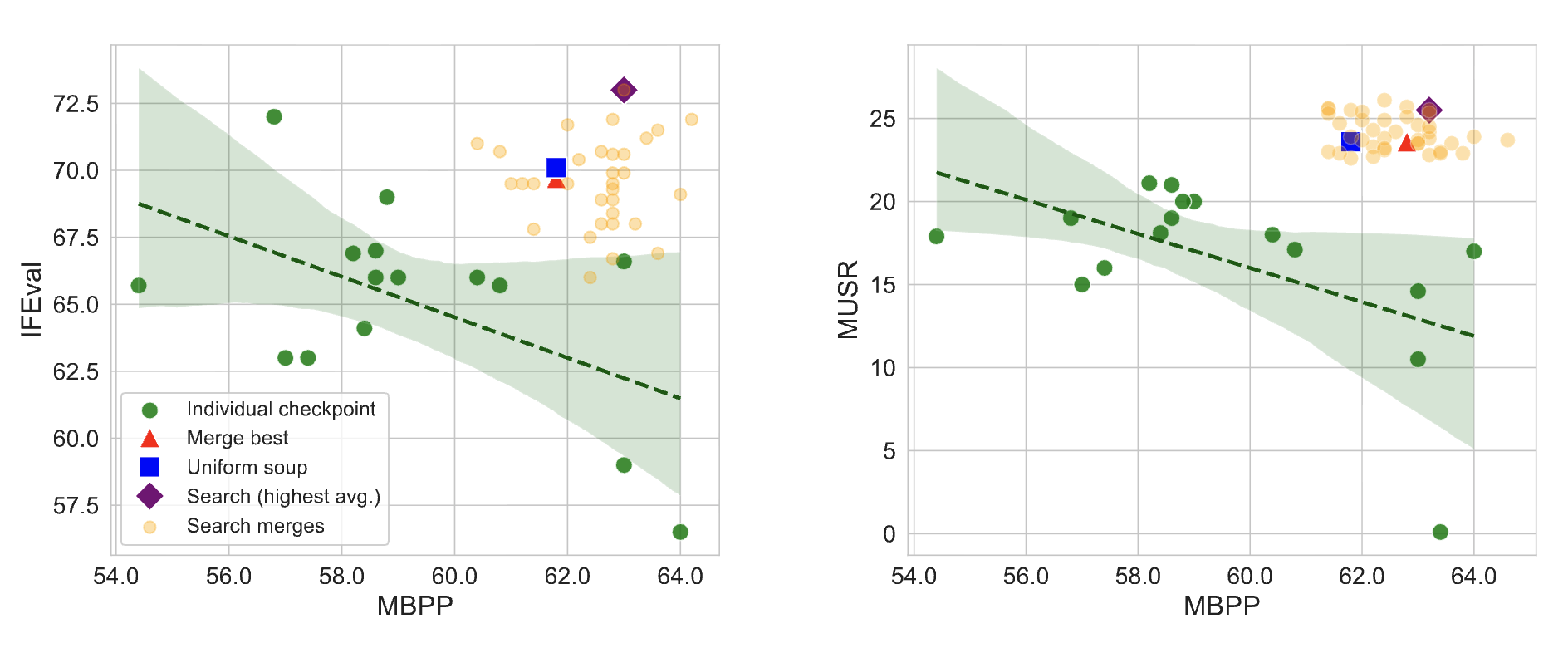
If You Can't Use Them, Recycle Them: Optimizing Merging at Scale Mitigates Performance Tradeoffs
Muhammad Khalifa, Yi-Chern Tan, Arash Ahmadian, Tom Hosking, Honglak Lee, Lu Wang, Ahmet Üstün, Tom Sherborne, Matthias Gallé
arXiv 2024